AI-generated answers are rapidly becoming a new discovery surface for the web. Instead of scanning a list of links, users increasingly receive synthesized responses from AI systems that summarize information from multiple sources.
For publishers, marketers, SEOs, and content teams, this creates a new question: how do you measure visibility in AI answers? Unlike traditional traffic channels, AI platforms don’t provide data about your performance in their results. (At least not yet.)
As a result, a growing number of tools are emerging to help site owners overcome this gap in data availability. But the methods these tools use to answer this question vary widely, from simulated data to “real” data grounded in signals from AI systems.
Understanding the difference between these two types of citation data—simulated AI visibility and real AI citation data —is becoming critical as teams try to understand their influence in the AI web.
The Rise of Synthetic AI Visibility Tools
The demand for AI visibility metrics has grown quickly, and the industry has responded with a wave of monitoring tools. Most of them use variations of the same technique: simulate prompts and analyze the answers.
Typically, these tools:
- Generate large batches of prompts related to a topic or keyword
- Submit those prompts to AI models or AI-powered search engines
- Scrape the responses for domain mentions or citations
- Estimate how frequently certain sites appear in answers
This approach can be helpful for gaining directional signals while exploring how a model might respond to certain questions. It can also reveal which sources are commonly referenced in particular scenarios. However, these simulations still represent constructed test environments, not actual AI usage.
In other words, they measure what an AI system could say when asked a particular question, not necessarily what it did say when a real user asked it.
The Limitations of Prompt Simulation
Synthetic prompt simulations can provide interesting signals, but they also introduce important limitations that teams should understand before relying on them as a source of truth.
1. Simulated prompts can’t capture real user behavior
Most simulators generate prompts based on keyword lists, templates, or heuristics. But real users phrase questions in unpredictable ways and often provide additional context within a conversation.
A simulated query like, “Best analytics tools for ecommerce” may look very different from a real user conversation such as: “We run Shopify and want to understand where users drop off in checkout. What analytics tools should we look at?”
Small differences in phrasing or context can lead AI systems to retrieve and cite completely different sources.
2. Outputs don’t reveal the retrieval layer
Modern AI answers are typically powered by a retrieval or grounding layer that pulls content from the web before generating the response.
Prompt simulators only see the final answer, not the underlying retrieval process that determined which sources were used.
That means they may miss:
- Sources that influenced the answer but weren’t explicitly cited
- Content retrieved during grounding but summarized away in the final output
- Signals about which pages were considered authoritative for a query
Without visibility into this layer, simulations provide only a partial picture of how AI answers are constructed.
3. AI responses change constantly
AI systems don’t produce the same output every time. Responses can vary based on:
- The model version
- Session context and prior conversation
- Ranking or retrieval updates
- Regional or platform differences
Two identical prompts sent minutes apart can produce different citations. As a result, simulations tend to capture snapshots of model behavior, not consistent patterns of real-world usage.
Measuring AI Visibility at the Source
In the era of the AI-mediated web, synthetic prompt simulation can be a useful tool, but site owners need a more grounded option for understanding their AI visibility.
To understand AI visibility more accurately, it helps to look beyond simulated prompts and examine how AI systems retrieve and cite information in real interactions.
When an AI system generates an answer grounded in web content, it typically follows a process that looks roughly like this:
- A user asks a question.
- The AI system retrieves relevant web content through a grounding or retrieval layer.
- The model synthesizes an answer using the retrieved information.
- Sources may be cited or referenced in the final response.
Each step produces signals that can reveal how content participates in AI-generated answers.
Rather than estimating citations through simulated prompts, measuring these signals provides visibility into how AI systems are interacting with real web content.
What Real AI Citation Data Looks Like
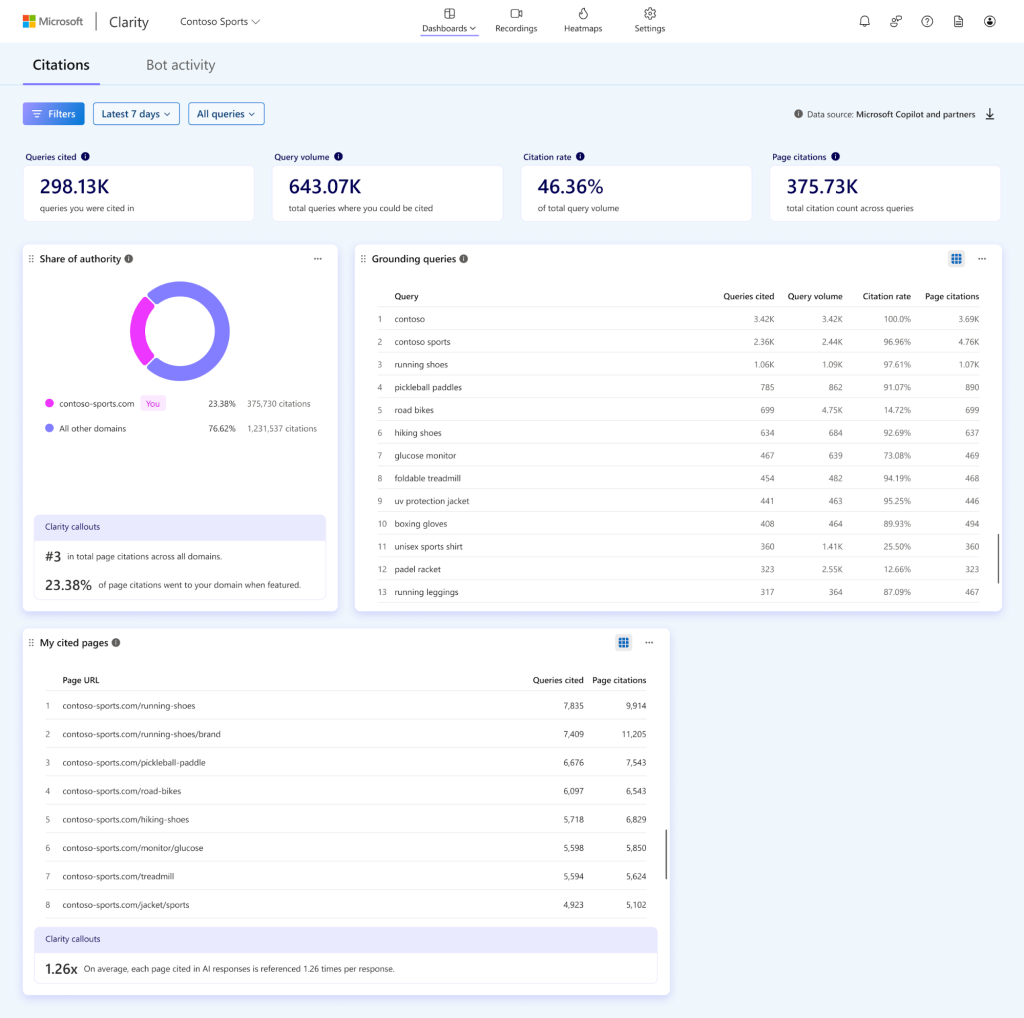
When AI visibility is measured using real interaction signals, the insights look very different from what prompt simulators typically provide.
Instead of asking “Did a model mention my site in a simulated prompt?”, teams can start answering more targeted questions:
- Which queries triggered AI answers that cited our content?
- How often does our content appear as a cited source?
- Which pages on our site are most frequently referenced?
- How does our citation share compare to competing sources?
This type of data reveals patterns that simulations often miss, such as:
- Pages that consistently influence AI answers even when they don’t drive traffic
- Topics where your content is frequently retrieved as a trusted source
- Emerging queries where AI systems rely on your site for information
It shifts the conversation from “Did we appear in a test prompt?” to “Where do we actually influence AI-generated knowledge?”
AI Visibility Is a Pipeline
Another important realization for teams studying AI traffic is that visibility in AI systems doesn’t happen in a single moment. It’s the result of a multi-step pipeline.
A typical path from web content to AI answers might include:
- AI bot crawling: AI systems discovering and indexing content across the web
- Content retrieval: relevant pages being selected to ground answers
- AI citations: sources referenced or attributed in generated responses
- AI-referred visits: users clicking through to learn more
Each stage provides a different signal about how content participates in the AI ecosystem.
Looking at only the final answer output, like most simulators do, ignores the earlier stages that often determine whether content becomes influential in the first place.
Understanding the full pipeline helps teams identify where opportunities exist to improve visibility.
The Next Phase of Web Analytics
For years, web analytics has focused primarily on measuring traffic: clicks, sessions, conversions, and engagement.
But AI-driven discovery is introducing a new layer of influence that happens before a user ever visits a website.
Content can now shape answers, recommendations, and summaries across AI systems, even when those interactions never result in a click.
Measuring that influence requires new types of signals and new ways of thinking about visibility.
The shift from simulated prompts to real AI interaction data represents an important step in that evolution. It moves the conversation from guessing how AI might behave to observing how AI systems actually use and cite web content.
And as AI continues to reshape the discovery experience, understanding that difference will become essential for anyone trying to understand their true presence on the AI-powered web.
To see how your content is actually cited in AI-generated answers, explore Microsoft Clarity’s AI Citations, which surfaces grounded citation signals from real AI interactions.