
Microsoft Clarity is a free analytics tool that helps website and app owners understand how users interact with their digital experiences—what they engage with, where they drop off, and what friction points may exist. Project administrators can easily install Clarity on their websites or mobile apps, and once set up, Clarity automatically captures visual snapshots and user interactions. Clarity processes millions of user sessions every day, presenting a massive challenge in terms of scale and performance. This data is then sent to Clarity’s backend, where it flows through a complex processing pipeline before ultimately being stored in ClickHouse—the powerful database that fuels Clarity’s dashboards and visual reporting.
In this blog, we’ll dive into how ClickHouse enables us to handle this scale efficiently and power a fast, responsive analytics experience.
Performance Challenges
Prior to the public launch, we had a proof-of-concept (POC) version that we used internally to track and monitor a few Microsoft websites. Back then, our infrastructure was quite different from what it is today. We relied on Elastic Search and Spark to power our dashboard graphs and visualizations. Ingestion throughput was very low, queries were so slow, heat map generation was an offline job, where users had to submit a request and wait around 30 minutes for the results. The system struggled to handle even a tiny fraction of our current traffic and was quite expensive to run.
When we decided to offer Clarity as a free public service, we knew it was time to revamp our infrastructure. We aimed to build a system robust and efficient enough to scale up to millions of projects, which means dealing with hundreds of trillions of events and hundreds of petabytes of data.
Handling such vast amounts of data is not an easy job. We need to ingest data at incredibly high speeds, apply complex calculations and aggregations to make sense of it all, and provide immediate insights to our customers. And moreover, we needed to do all of this without losing any granularity, so we can enable the users to filter on the finest details.
All of that imposed a real technical challenge for Clarity which turned us towards ClickHouse to ultimately meet our goals.
Why did we choose ClickHouse?
In October 2020, we proudly launched Clarity, with ClickHouse at its core from day one. This decision was not made lightly; it was the result of extensive research, thorough investigations, numerous experiments, and careful consideration of various trade-offs.
Compared to our POC system, ClickHouse outperformed Elastic Search and Spark in every aspect. Heat map generation became an instantaneous task to do, and it was even orders of magnitude cheaper to run. This is the reason why many products have migrated from Elastic Search to ClickHouse, experiencing significant enhancements in their services as a result.
Not only did we compare ClickHouse against Elastic Search and Spark, but also against several other alternatives, and the following are the primary reasons why we chose ClickHouse over other available databases:
- Ingestion Performance: utilizing its
MergeTreeengine, ClickHouse can support very high ingestion throughput, meeting the huge load of Clarity.
- Query Performance: being extremely fast and efficient, ClickHouse can aggregate billions of rows and return results in milliseconds. Efficiency also translates to cost savings in terms of compute resources, as we need less machines to achieve the same job.
- Storage Efficiency: offering amazing data compression while being a column-oriented database resulted in significant cost savings in terms of storage. Additionally, ClickHouse supports storage policies where you can define hot and cold disks for further cost savings.
- Scalability: being a distributed master-master database, with the support of replication, it is easy to scale our cluster horizontally when needed to cater for the increase of traffic.
- Community: being open source, committing to monthly release cycles, and having such an active support team replying to all of our questions and inquiries on different channels (GitHub and Telegram) gave us more confidence in ClickHouse. In fact, we also contributed to the project and marked our names in the
system.contributorstable.
- Moreover, ClickHouse was designed for OLAP scenarios, specifically to support Yandex.Metrica, which has a similar use case to Clarity, providing assurance in its capabilities.
However, adopting ClickHouse wasn’t entirely seamless, it came with its own set of challenges that we had to navigate. The biggest of which was its high operational cost. Although ClickHouse is very efficient in terms of compute & storage costs, we had to pay for self-managing and operating the cluster ourselves.
ClickHouse Challenges
Our main challenge or trade-off with ClickHouse was hosting, operating, and managing everything ourselves. As a new team, we needed to focus on the business logic of Clarity and less on hosting. We lacked expertise in hosting and were accustomed to Azure’s managed services. For instance, creating a NoSQL database in Azure is simple; a few clicks handle provisioning, scalability, replication, security, monitoring, backups, and recovery; all is done out-of-the-box with no hassle. But at the time we launched Clarity, ClickHouse wasn’t available as a managed service on Azure, so we had to manage it all independently, creating numerous tools, automations, and services around ClickHouse.
Clarity’s Architecture
ClickHouse
To handle the huge scale of Clarity, our ClickHouse setup is a massive cluster consisting of hundreds of machines. These machines are divided into distinct sub-clusters, or what we call layers, each dedicated to serving a specific subset of projects. This structure ensures that each project’s data is contained within its assigned layer alone, providing clear and efficient data management. Despite operating independently, these layers are interconnected to facilitate cross-project queries and simplify the overall management.
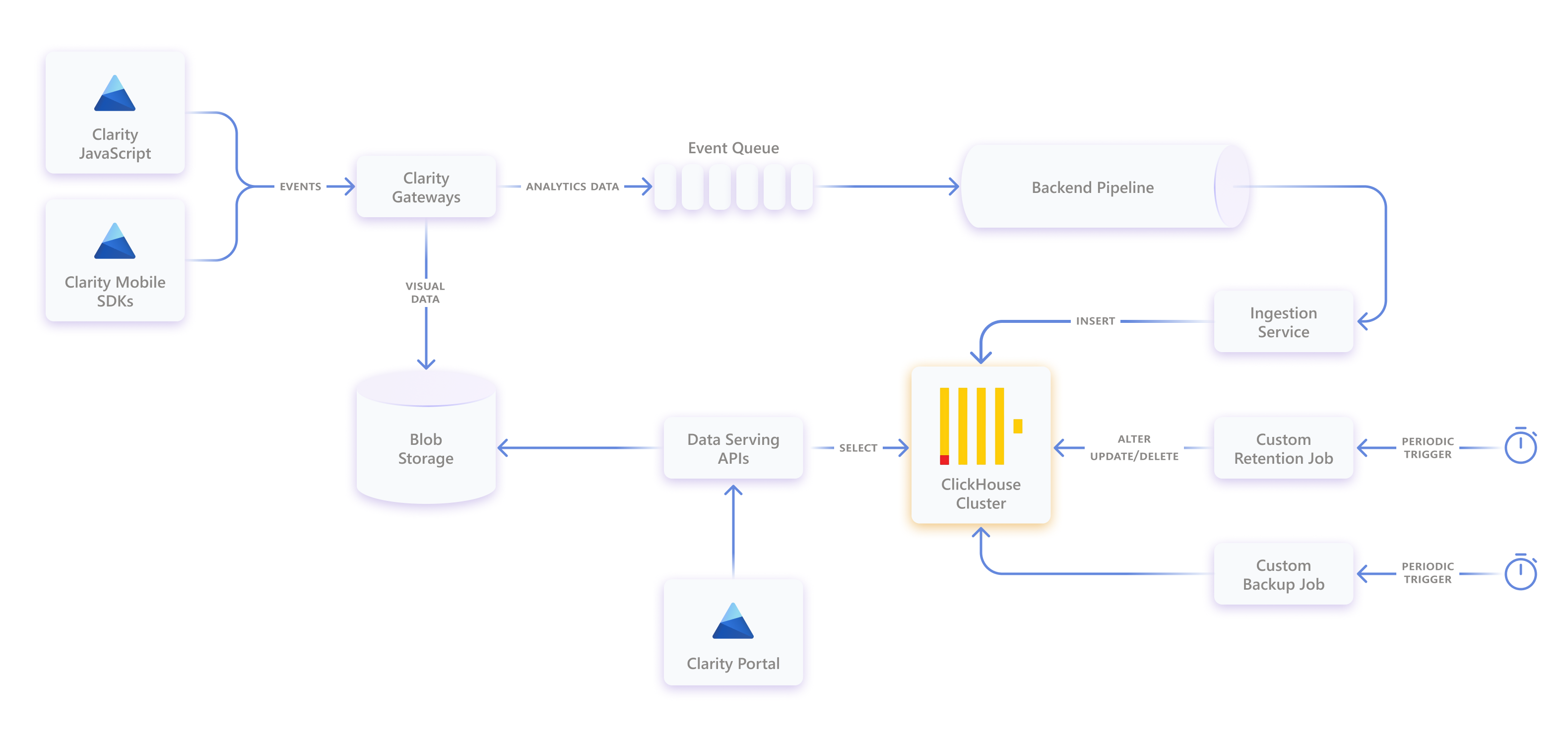
For higher data reliability, availability, and performance, our data is replicated across data centers. The entire cluster relies on a single ZooKeeper ensemble with three nodes to facilitate this replication and synchronization process.
In order to achieve high ingestion throughput with excellent querying performance, the data is primarily stored in a large ReplicatedMergeTree table, supplemented by other secondary tables. MergeTree table engines are the most widely used and robust engines in ClickHouse, designed specifically for high data ingest rates and large data volumes. The ReplicatedMergeTree table engine is a standard MergeTree engine with added replication support. The design involved careful choice of the partition and primary keys to improve the index performance and data compression. Furthermore, materialized views were employed over the main table to optimize certain querying scenarios by restructuring and aggregating data accordingly.
To ensure data integrity and compliance, regular backups are taken for the entire cluster, and custom data retention policies are enforced through periodic mutations.
Ingestion
The ingestion path of Clarity starts with JavaScript and mobile SDKs; they collect:
- Visual information of your app such as the DOM for web apps and the view hierarchy for mobile apps.
- User interactions such as mouse movements, clicks, scrolls, and so on.
These data are then sent to our fast lightweight backend gateways where two main things happen:
- The visual and playback data is stored in blob storage.
- The interaction and analytics data is queued for further processing.
The analytics part of the data undergoes a lot of processing, aggregation, and transformation before being stored at ClickHouse.
We developed a dedicated service that buffers incoming data in large batches before routing it to the appropriate machines in the cluster. This approach was chosen over the native ClickHouse Buffer table, which is prone to data loss during abnormal server restarts.
Consumption
The consumption path, on the other hand, is much simpler. All the panels, charts, and heat maps in the portal are powered by ClickHouse. The portal retrieves the required aggregated data from our serving APIs, which is just a simple abstraction over ClickHouse. Previously, we were using Chproxy which is an open-source proxy and load balancer for ClickHouse, but then we needed a custom service to support our custom bi-sharding (i.e., layering). Later, additional functionalities were introduced to that service such as rate limiting, enhanced logging, and more.
Conclusion
Microsoft Clarity has proven to be an invaluable tool for website and app owners, providing deep insights into user interactions and engagement. The journey to build Clarity was filled with challenges that demanded extensive research, thorough investigations, numerous experiments, and careful consideration. Leveraging ClickHouse as the core database solution has enabled Clarity to overcome significant performance challenges. Despite the trade-offs, the benefits have been substantial, making Clarity a robust, efficient, and scalable system that supports millions of projects, dealing with hundreds of trillions of events and hundreds of petabytes of data.
As we continue to evolve and improve, Clarity remains committed to delivering immediate and detailed insights to help our users optimize their digital experiences and achieve their goals, all while being free.